The primary index for a table controls the distribution and retrieval of the data for that table across the AMPs. Both distribution and retrieval of the data is controlled using the Teradata Database hashing algorithm. If the primary index is defined as a partitioned primary index (PPI), the data is partitioned, based on some set of columns, on each AMP, and ordered by the hash of the primary index columns within the partition. Data accessed based on a primary index is always a one-AMP operation because a row and its index are stored on the same AMP. This is true whether the primary index is unique or nonunique, and whether it is partitioned or nonpartitioned.
Primary Index Assignment
In general, most Teradata Database tables require a primary index. To create a primary index, use the CREATE TABLE statement. If you do not assign a primary index explicitly when you create a table, Teradata Database assigns a primary index, based on the following rules.
A unique index, like a primary key, has a unique value for each row in a table. Teradata Database defines two different unique indexes:
The benefits of unordered data include:
Primary Index Assignment
In general, most Teradata Database tables require a primary index. To create a primary index, use the CREATE TABLE statement. If you do not assign a primary index explicitly when you create a table, Teradata Database assigns a primary index, based on the following rules.
- If column has defined Primary key then Teradata will make it UPI.
- if columns having a UNIQUE constraint then Teradata will make it UPI.
- if column or columns having a UNIQUE constraint to be a UPI.
A unique index, like a primary key, has a unique value for each row in a table. Teradata Database defines two different unique indexes:
- Unique primary index (UPI)
- Unique secondary index (USI)
The benefits of unordered data include:
- No maintenance needed to preserve order, and
- It is independent of any query being submitted.
- Distribution is the same regardless of data volume
- Distribution is based on row content, not data demographics
- Indexes are conceptually different from keys.
- A PK is a relational modeling convention which allows each row to be uniquely identified.
- A PI is a Teradata convention which determines how the row will be stored and accessed.
- A significant percentage of tables may use the same columns for both the PK and the PI.

Distribution of Rows

Primary Index
There are two type of primary Index
- Unique Primary Index
- Non Unique Primary Index

Indexes can facilitate access to data of interest in a database. Teradata Database offers several different types of indexes that can help to optimize the performance of your relational databases.
- Teradata uses hash algorithm to randomly distribution and evenly distribute data across all AMPs.
- The Primary index choice determines whether the rows of a table will be evenly or unevenly distributed across the AMPs.
- Evenly distributed table rows result in evenly distributed workloads.
- Each AMP is responsible for a subset of the rows of each table.
- The data is not placed in any particular order
The benefits of unordered data include:
- No maintenance needed to preserve order, and
- It is independent of any query being submitted.
The benefits of hash distributing include :
- Distribution is the same regardless of data volume
- Distribution is based on row content, not data demographics
Every table in Teradata is designed to have a column that represents the Primary Index. This is the fastest index in the table and will always result in a Single-AMP retrieve. The Primary Index is used to place the row on a particular AMP and therefore it is easy for Teradata to know which AMP has that row, so when a query uses the Primary Index column‘s value in the WHERE clause of the SQL the Parsing Engine knows which AMP to contact to retrieve the row.


Teradata uses the Primary Index of each table to provide a row its destination to the proper AMP. This is why each table in Teradata is required to have a Primary Index. The biggest key to a great Teradata Database Design begins with choosing the correct column to be the Primary Index. The Primary Index columns value is the only thing that will determine on which AMP a row will reside.The Primary Index does determine data distribution, but even more importantly, the Primary Index provides the fastest physical path to retrieving data. The Primary Index also plays an incredibly important role in how joins are performed. Teradata allows up to 64 combined columns to make up the one Primary Index required for a table.

There are two types of primary index.
- Unique Primary Index (UPI)
- Non Unique Primary Index (NUPI).
Non Unique Primary Index(NUPI)
A Non-Unique Primary Index (NUPI) means that the values for the selected column can be non-unique. A Non-Unique Primary Index will almost never spread the table rows evenly. We have selected LAST_NAME to be our Primary Index. Because we have designated LAST_NAME to be a Non-Unique Primary Index we are anticipating that there will be individuals in the table with the same last name. An All-AMP operation will take longer if the data is unevenly distributed. You might pick a NUPI over an UPI because the NUPI column may be more effective for query access and joins.
In the following figure you can see we have designated First_Name and Last_Name combined to make up the Primary Index. This is often done for two reasons:
- To get better data distribution among the AMPs
- Users often use multiple keys consistently to query
If no Primary Index is defined the system will define one for you. It will most likely pick the first column and make it a Non-Unique Primary Index (NUPI).It will however check to see if you have a Primary Key defined for referential integrity purposes. If you do it will choose that column(s) and make it a Unique Primary Index (UPI). If you didn‘t define a Primary Index or Primary Key then the system will check to see if you defined a Unique Secondary Index (USI) on any column and if you have it will make that column a Unique Primary Index (UPI).
Laying out and Retrieving Data
Teradata freed the AMPs from doing everything together by giving each table a Primary Index. The Primary Index is the column(s) that lays out the data row to the proper AMP and the Primary Index column(s) is also the fastest way to retrieve a row from that same AMP. Teradata takes a table and spreads the rows across the AMPs one row at a time. A Unique Primary Index on the table will spread the data rows perfectly evenly across the AMPs. This is pretty amazing in itself, but the more amazing part is that Teradata knows exactly which rows went to which AMPs so retrieval is always a 1-AMP operation when users use the Primary Index in the WHERE Clause of their SQL.

The Teradata Parsing Engine will take the Primary Index Value of a row and run a math calculation called the Hash Formula on that Primary Index column value.
Teradata then has a Hash Map with one million buckets. Inside the buckets are AMP numbers. So, when the Hash Formula is calculated on the value of the column designated as the Primary Index, and the result is for example 20,Teradata will go to bucket 20 of the Hash Map, look inside bucket 20 and see which AMP it says should get the row.
Hashing the Primary Index Value
SELECT *
FROM Employee_Table
WHERE Emp_No = 2 ;
The Parsing Engine knows Emp_No is the Primary Index so it Hashes the value of 2 with the Hash Formula, comes up with a 000000000101 Row Hash, which equates to a 5, and then goes to bucket 5 in the Hash Map, which then tells the PE which AMP holds that row.

An 8-AMP Hash Map Example

In this we example we have taken 8-AMP system. Notice how the numbers 1, 2, 3, 4, 5, 6, 7, 8 keep repeating inside all one million buckets.
Every Teradata System has one Hash Map with a million buckets. Inside the buckets are AMP numbers.
The AMP numbers don‘t change inside the Hash Map. They are static.
The Hash Formula on the Primary Index value of 2 gives the result is a Row Hash of 000000101, which is equal to 5.
Teradata would count over 5 buckets and look inside bucket number 5.That would tell the PE to place the row on AMP 5 in this system.
On the below pic you see that the user has run a query looking for all columns in the Employee_Table where the Emp_No = 2. The Parsing Engine knows that Emp_No is the Primary Index and comes up with a 1-AMP Plan.Teradata Hashes the Primary Index Value of 2 and receives an answer set called the Row Hash, which is calculated to be 000000101, which equates to a 5. Teradata counts over 5 buckets in the Hash Map and the system tells the BYNET to contact AMP 1.


Teradata hashes the Last_Name value of =Lacy‘ and once again it comes up with a 32-bit Row Hash. The Row Hash value is 00000000000001100, which equates to a 12. Teradata will go to the Hash Map and looks inside bucket 12 and then know which AMP to place the row. This is a math formula that is always consistent so every person with a last name of Lacy goes to the same AMP. This is because the Hash Formula is run on all three Lacy‘s in the example and all three Lacy‘s came up with the same Row Hash, therefore went to the same bucket in the Hash Map, and therefore were directed to the same AMP.
The last names in this table have three people named =Lacy‘ and two people named =Jones‘. Each of the rows with the name =Lacy‘ went to AMP 4 and everyone named =Jones‘ went to AMP 2. Duplicate values Hash the same and they point to the same bucket in the Hash Map, so they always go to the same AMP.
If we had more people in the table named =Lacy‘ they would all continue to go to AMP 4. If there were 1,000,000 people named =Jones‘ they would all end up on AMP 2.
Hashing Non-Unique Primary Indexes (NUPI)


Teradata hashes the Last_Name value of =Lacy‘ and once again it comes up with a 32-bit Row Hash. The Row Hash value is 00000000000001100, which equates to a 12. Teradata will go to the Hash Map and looks inside bucket 12 and then know which AMP to place the row. This is a math formula that is always consistent so every person with a last name of Lacy goes to the same AMP. This is because the Hash Formula is run on all three Lacy‘s in the example and all three Lacy‘s came up with the same Row Hash, therefore went to the same bucket in the Hash Map, and therefore were directed to the same AMP.
Remember, there is only one Hash Formula and only one Hash Map. That is the only problem with a NUPI. It can cause uneven distribution and often one AMP gets many more rows then the other AMPs. This is called a "Hot AMP" or "Data Spike".


Teradata hashes the Last_Name value of =Lacy‘ and once again it comes up with a 32-bit Row Hash. The Row Hash value is 00000000000001100, which equates to a 12. Teradata will go to the Hash Map and looks inside bucket 12 and then know which AMP to place the row. This is a math formula that is always consistent so every person with a last name of Lacy goes to the same AMP. This is because the Hash Formula is run on all three Lacy‘s in the example and all three Lacy‘s came up with the same Row Hash, therefore went to the same bucket in the Hash Map, and therefore were directed to the same AMP.
The last names in this table have three people named =Lacy‘ and two people named =Jones‘. Each of the rows with the name =Lacy‘ went to AMP 4 and everyone named =Jones‘ went to AMP 2. Duplicate values Hash the same and they point to the same bucket in the Hash Map, so they always go to the same AMP.
If we had more people in the table named =Lacy‘ they would all continue to go to AMP 4. If there were 1,000,000 people named =Jones‘ they would all end up on AMP 2.
The Row-ID


When the row is placed on the AMP the Row Hash that was derived by Hashing the Primary Index will be placed at the front of the row. The AMP will sort the rows that it owns for the table by the Row Hash. Every Row will be kept in a perfect order on the AMP by sorting by the Row Hash.
The AMP will also add a Uniqueness Value behind the Row Hash so it can keep track of duplicate values.When a row comes in with its Row Hash the AMP will check to see if it has any other Row Hashes exactly like the one it has just received. If this Row Hash is Unique it will put a 1 as the Uniqueness value. If it already has another Row Hash just like this one it will put a 2 in the Uniqueness value. If this Row Hash is the third duplicate it will put a Uniqueness value of 3, etc., etc., etc.
For example, if there are 1000 duplicate Primary Index values such as the Last_Name of =Smith‘, then they would each have the same Row Hash and go to the same AMP. Their Row Hash would be the same, but their Uniqueness Value would range from 1 to 1,000.


The Row ID
The Row Hash and the Uniqueness Value make up the Row ID. Teradata rows placed on an AMP always have the Row ID at the beginning of every row. Each AMP actually sorts their rows by the Row ID, not just the Row Hash.
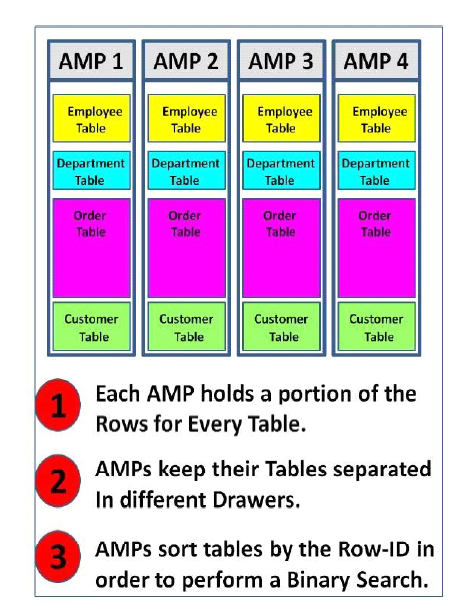
A Visual data Layout
Each AMP holds a portion of a table. Each AMP keeps the tables in their own separate drawers. The Row ID is used to sort each table on an AMP.
- Each AMP holds a portion of every table.
- Each AMP keeps their tables in separate drawers.
- Each table is sorted by Row ID.
CREATE SET VOLATILE TABLE AF62752.EMP ,NO FALLBACK , CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO, LOG ( EMP_ID INTEGER NOT NULL, NAME VARCHAR(10) CHARACTER SET LATIN NOT CASESPECIFIC NOT NULL, SSN CHAR(11) CHARACTER SET LATIN NOT CASESPECIFIC NOT NULL, GENDER CHAR(1) CHARACTER SET LATIN NOT CASESPECIFIC NOT NULL, STATE CHAR(2) CHARACTER SET LATIN NOT CASESPECIFIC NOT NULL, VALID_FROM DATE FORMAT 'YY/MM/DD' NOT NULL, VALID_TO DATE FORMAT 'YY/MM/DD') PRIMARY INDEX ( EMP_ID ,VALID_FROM ) ON COMMIT PRESERVE ROWS ; INSERT INTO EMP (EMP_ID,name,ssn,gender,state,valid_from,valid_to) VALUES (14, 'Jo' , '323-10-1116', 'F', 'MI', '1998-12-03', '1998-12-27') ; INSERT INTO EMP (EMP_ID,name,ssn,gender,state,valid_from,valid_to) VALUES (14, 'Jo' , '323-10-1119', 'F', 'MI', '1998-12-28', '2005-04-22') ; INSERT INTO EMP (EMP_ID,name,ssn,gender,state,valid_from,valid_to) VALUES (14, 'Joe' , '323-10-1119', 'F', 'MI', '2005-04-23', '2005-08-07') ; INSERT INTO EMP (EMP_ID,name,ssn,gender,state,valid_from,valid_to) VALUES (14, 'Joseph', '323-10-1119', 'M', 'MI', '2005-08-08', '2006-02-12') ; INSERT INTO EMP (EMP_ID,name,ssn,gender,state,valid_from,valid_to) VALUES (14, 'Joe' , '323-10-1119', 'M', 'MI', '2006-02-13', '2006-07-04') ; INSERT INTO EMP (EMP_ID,name,ssn,gender,state,valid_from,valid_to) VALUES (14, 'Joseph', '323-10-1119', 'M', 'NY', '2006-07-05', '2006-12-24') ; INSERT INTO EMP (EMP_ID,name,ssn,gender,state,valid_from,valid_to) VALUES (14, 'Joseph', '323-10-1119', 'M', 'MI', '2006-12-25', NULL) ; INSERT INTO EMP (EMP_ID,name,ssn,gender,state,valid_from,valid_to) VALUES (15, 'Jim' , '224-57-2726', 'M', 'IL', '2002-01-16', '2004-03-15') ; INSERT INTO EMP (EMP_ID,name,ssn,gender,state,valid_from,valid_to) VALUES (15, 'James' , '224-57-2726', 'M', 'IL', '2004-03-16', '2007-06-22') ; INSERT INTO EMP (EMP_ID,name,ssn,gender,state,valid_from,valid_to) VALUES (15, 'James' , '224-57-2726', 'M', 'IN', '2007-06-23', '2007-08-31') ; HELP TABLE EMP;
No comments:
Post a Comment